Network Compression
Several studies have shown the presence of significant redundancy in network traffic content. These studies clearly establish the tremendous scope for enhancing communication performance through exploitation of the redundancies. In this research, we introduce the concept of Network Compression via Network Memory. In the nutshell, network compression enables memorization of data traffic as it flows naturally (or by design) through the network. As such, memory enabled nodes can learn the source statistics which can then be used toward reducing the cost of describing the source in compression.
We have proposed practical algorithms for network compression. We reported a memorization gain (defined as the additional redundancy elimination gain on top and over what can be achieved by the existing compression techniques) of order three when the algorithms are tested on the real Internet traffic traces. Furthermore, we investigated the deployment of memory in both random and Internetlike power-law graphs on real traffic. Our study showed significant network-wide gain of memorization even when a tiny fraction of the total number of nodes in the network is equipped with memory.
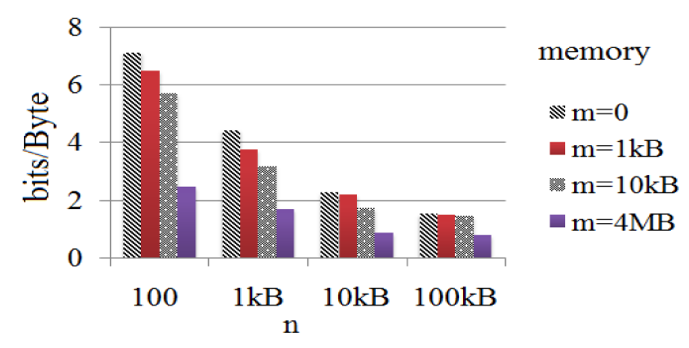 Compression of Internet data via CTW scheme: without memory m=0 and with memory (i.e. m>0)
Compression of Internet data via CTW scheme: without memory m=0 and with memory (i.e. m>0)
Network packet compression (at layer 3 or network layer) is a new paradigm with profound impacts in many applications ranging from efficient content delivery between data centers, in clouds and peer to peer networks to cellular, Wi-Fi and wireless sensor networks. We plan to tackle some of the requirements that will pave the way for the application of network packet compression via memory in these areas. In particular, we study several theoretical and practical research problems raised in packet compression, i.e., universal compression in finite-length regimes:
Seismic Compression
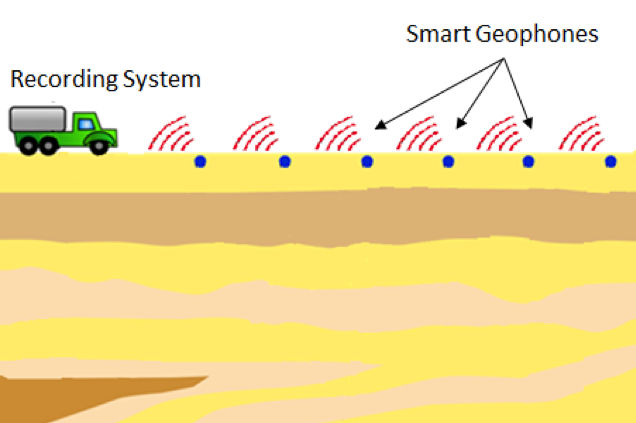
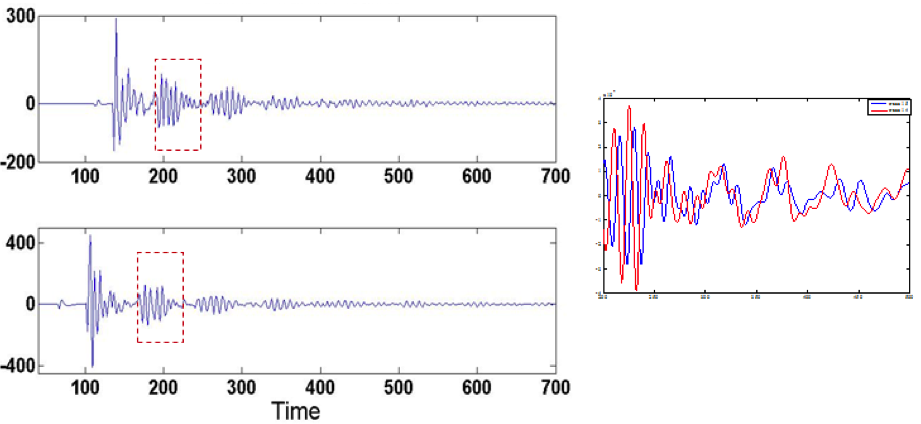
The traditional seismic acquisition systems use passive recording devices and place all the processing at the data centers, hence require lots of data to be transferred from sensors to the recording systems. The trend for the future generations of seismic data acquisition is to have 1. Large scale seismic acquisition, which will produce a large amount of data to be collected daily, 2. Real time acquisition and quality assessment, and 3. Automation and adaptive seismic acquisition. Since cabling and labor costs constitute more than half of the costs of seismic acquisition, we propose to explore wireless seismic data acquisition. To meet the bandwidth and latency challenges, we propose to deviate from the traditional systems, by placing intelligence at the field by employing some processing power in the sensors.
In this project, we investigate data compression techniques in the field for the transfer and storage of large scale seismic data via wireless networks. Specifically, we propose removing inter and intra trace redundancies (i.e., temporal and spatial correlations) in universal and distributed manner, without requiring any coordination among sensors. The premise of our proposed approach lies on learning from the seismic data on the go and utilizing this knowledge toward universal (near) lossless compression of the original traces. This approach is designed to address the key constraints of the network and recording system while maintaining the desirable objectives (e.g., locality of traces).
In summary, there is a need for bringing new advances in seismic acquistion systems. Our group particularly studies the following critical topics:
Model Complexity Reduction of Deep Neural Networks
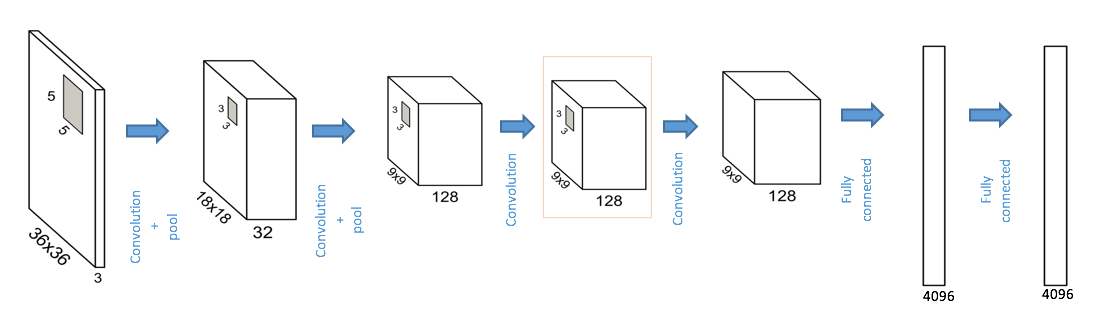
The sizes of neural networks have been growing rapidly as the complexity of the problems that they solve and the size of data keep increasing every year. They require more resources for the storage and computations. This problem compounds as deep neural networks become popular for solving challenging data analytic problems. Our objective is to substantially reduce the number of parameters required to represent a deep neural network without sacrificing predictive accuracy. For example, deep networks such as AlexNet has 61 million parameters, requiring 200 MB of memory. Clearly, such a memory requirement is very undesirable for many applications as it consumes a large amount of power due to off chip storage. Further, a deep network is composed of layers with very different properties. Convolutional layers, which contain a small fraction of the network parameters, yet require large computational effort. In contrast, fully connected layers contain the vast majority of the parameters and are dominated by data transfer. This imbalance between memory and computation suggests that we must address the efficiency of these two types of layers differently.
We propose to leverage on neural network redundancies and develop a method to jointly quantize and compress large neural network models so that they can be fit in much smaller memory sizes (e.g., possibly in chip memory). This can significantly improve power consumption as well as latency of the computations over large neural networks.