Neuro-Symbolic Reinforcement Learning via Logical Reasoning

Deep reinforcement learning (RL) algorithms have achieved remarkable success, even super-human performance, in some limited scenarios. Despite all these advances, deep RL systems rarely exhibit the most basic of human cognitive functions such as causal inference, spatial-temporal reasoning, or generalization. As such, it is still unclear as to how we can efficiently develop powerful systems that are highly certain to have desirable objectives. A central objective in this project is building stronger RL solutions that can learn reliable and generalizable policies, robust to unseen real-world data with possible shifts. This is indeed a very challenging task, especially when the input space is high-dimensional or continuous, such as with visual data, and the environment is only partially observed. Inspired by this objective, we seek to explore a hybrid reinforcement learning paradigm that combines the expressive power of deep neural networks to encode world models and agent action spaces with an inductive logic capability that can dynamically organize the relational structure between world observables and agent policies and actions. The proposed hybrid solution, hereafter referred to as Neuro-symbolic Hierarchical RL, benefits from a novel hierarchical framework for Symbolic Reinforcement Learning (SRL) that is developed based on our recent work on Differentiable Neural Logic Inductive Logic Programming (dNL-ILP) and temporal reasoning, as well as modern data-driven transformer-based World Modeling to utilizes both statistical and symbolic knowledge. The main idea behind our research is to upgrade the typical implicit representation used in traditional RL to the first-order spatial-temporal relational form in program logic. As such, the agent would be able to describe the environment more naturally in terms of objects and (spatial-temporal) relations, and hence learn the actions and policies by inductive logical reasoning over those spatial-temporal relations. This mechanism for causal or analogical reasoning is of significant importance specially in reusing across tasks. In particular, we can develop agents that rely less on data from interactions, that are costly, and instead be able to reason over observations in their problem solving.
Hierarchical Reinforcement Learning using Inductive Logic Programming
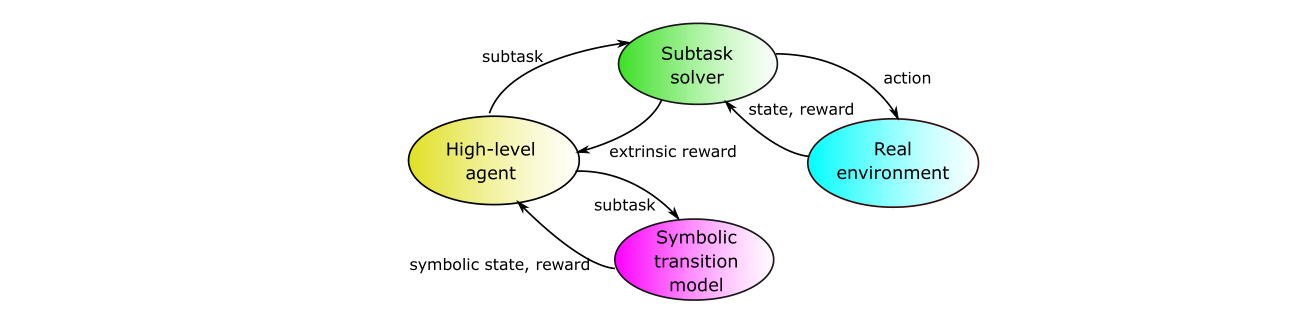
Recent works suggest that Hierarchical RL (HRL) is a promising approach to reduce sample complexity and scale RL to long-horizon tasks. The idea is to use a high-level policy to generate a sequence of high-level goals, forming subtasks or options, and then use low-level policies to generate sequences of actions to solve every subtask/options. By abstracting many details of the low-level states, the high-level policy can efficiently plan over much longer time horizons, reducing sample complexity in many tasks. Different from previous work on HRL with symbolic planning, we introduced a framework which does not need any prior knowledge on symbolic transitions in the high-level part. Instead, by reasoning via our differentiable inductive logic program framework dNL-ILP, we adopt the model-based RL which learns a transition model of the high-level symbolic states via logical reasoning via ILP and utilize this model to generate a subtask/option. The results implies that our option framework is superior to other baseline hierarchical methods. It also implies that the symbolic transition model learned in the training to represent the high-level dynamics of the problem is performing superior in testing experiments, verifying the generalization capability of our ILP based option framework. The results on learning rate during training also suggested significant acceleration in learning by our ILP based option framework.
Relational Reinforcement Learning via an Abductive-Inductive Framework
In recent years and with the advent of the new deep learning techniques, significant progress has been made on the deep Reinforcement Learning (RL) framework. By using algorithms such as deep Q-learning and its variants, as well as policy learning algorithms such A2C and A3C, more complex problems have been solved. However, there are some areas where the deep RL framework has some notable shortcomings. For example, most of the deep RL systems learn policies that are not interpretable. Further, generalization is usually poor. Finally, they are strictly reactive and they do not use high level planning and causal and logical reasoning. Relational Reinforcement Learning (RL) offers various desirable features. Most importantly, it allows for incorporating expert knowledge and inductive biases, and hence leading to faster learning and better generalization compared to the standard deep RL. However, existing RRL approaches usually require an explicitly relational state for the environment. As such, these models can not directly learn policies for the visual environments where the observation is in the form of non-relational data such as images. In this project, we propose a novel abductive inductive relational RL framework that extends the applicability of the RRL to the visual domains. We learn the relational state of the environment via logical abduction and we use a differentiable implementation of inductive logic to generate a relational policy. The resulting framework processes the visual observations from the environment similar to the deep RL (e.g. using convolutional neural networks), but learns the policy and generates actions via a differentiable inductive logic solver, in an end-to-end learning paradigm. We show the efficacy of this framework using visual RL environments such as BoxWorld, Grid- World, and Asterix Atari game. Finally, we show how the same principle can be used in other supervised tasks via an experiment on Sort-of-CLEVR dataset.
Reinforcement Learning through Non-Expert Human Feedback
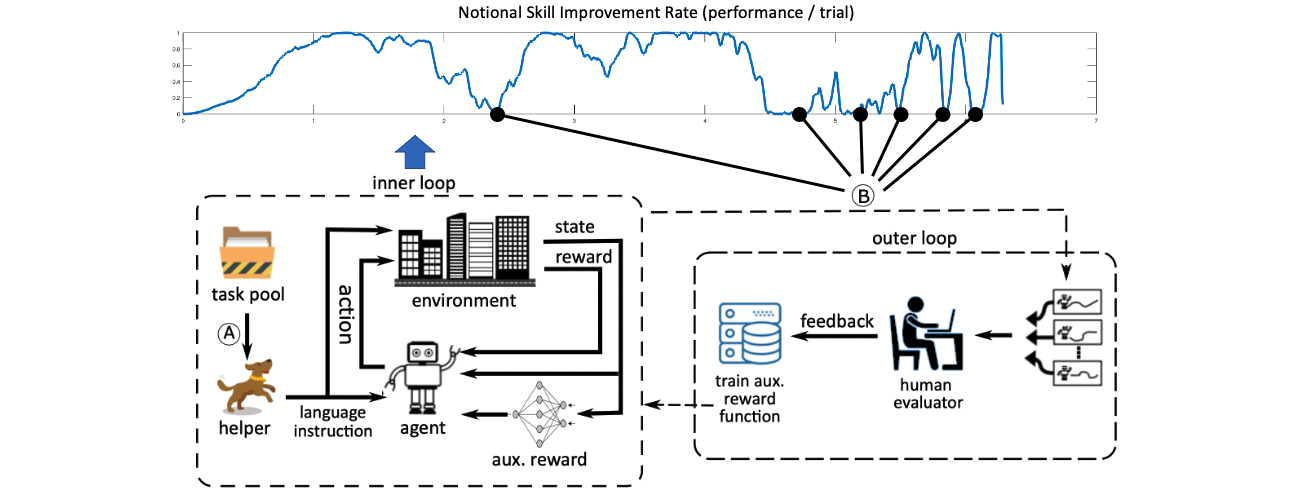
Deep reinforcement learning (RL) algorithms have achieved remarkable success, even super-human performance in many fields. Despite all these advances, it is still unclear as to how we can efficiently develop powerful systems that are highly certain to have desirable objectives. Inspired by this challenge, we seek to explore how naive human feedback can be employed in three inter-related advanced AI problems to effectively and efficiently attain desirable objectives: (1) Multi-task RL: Most of the prior success in RL systems is achieved by single-task learning algorithms, an approach that has been found to be less effective when employed in multiple task applications. At a practical level, the application of these algorithms to real-world problems is still restricted by the difficulty of transferring the learned RL agent skills from one task to another. (2) Safe RL: In many practical problems, such as robotic control and autonomous driving, the agent’s behavior must satisfy safety constraints. In other words, it needs to avoid undesired states, or undesired state sequences. Existing solutions which rely on negative rewards, handcrafted policies, shielding mechanisms are, however, either tedious, inadequate, or overly conservative to effectively satisfy safety constraints. (3) Lifelong RL: Current RL algorithms primarily achieve impressive performance by mastering a narrow task of interest, often through nuanced artifacts unique to the training environment. However, the deployed agent then lacks the state-action space representations required to generalize to new variations. Continual RL is supposed to train the agent to continually learn and adapt to both new tasks and environments over the duration of the lifetime. However, current lifelong RL solutions still rely on Markovian state dynamics. Therefore, such solutions are unfit for important domains, such as embodied by the complexity of procedurally generated games or partially observed Markov Decision Processes. In all these research problems, we wish to discover how we can leverage intrinsic capability and common sense of a non-expert human to democratize training of complex RL systems efficiently and without burdening the human. As a result, the RL systems would be accessible by ordinary people who are neither an expert in machine learning nor required of understanding the complex dynamics of the AI task for generating feedback that is needed to achieve desirable objectives. Our solutions are inspired by incorporating logical reasoning and first-order predicate logic representation of policy that is interpretable by human in the loop and can facilitate human interactions.
Generalization of Temporal Logic Tasks in RL via Future Dependent Options
In many real-world applications of control system and robotics, temporal logic (TL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviors across tasks, including conditionals and alternative realizations. An important problem in RL with TL tasks is to learn task-conditioned policies which can zero-shot generalize to new TL instructions not observed in the training. However, it is often inefficient or even infeasible to train reinforcement learning (RL) agents to solve multiple TL tasks, since rewards in these tasks are sparse and non-Markovian. In order to tackle these issues, our research develops a novel option-based framework to generalize TL tasks. To address the sub-optimality issue, we propose to learn options dependent on the future subgoals via a novel approach. To address the inefficiency issue, we propose to train a multi-step value function which can propagate the rewards of satisfying future subgoals more efficiently in long-horizon tasks. In experiments on three different domains, we evaluate the generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Symbolic Planning for Following Temporal Logic Specifications in RL
Teaching a deep reinforcement learning (RL) agent to follow instructions in multi-task environments is a challenging problem. We consider that user defines every task by a linear temporal logic (LTL) formula. However, some causal dependencies in complex environments may be unknown to the user in advance. Hence, when human user is specifying instructions, the robot cannot solve the tasks by simply following the given instructions. In this work, we propose a hierarchical reinforcement learning (HRL) framework in which a symbolic transition model is learned to efficiently produce high-level plans that can guide the agent efficiently to solve different tasks. Specifically, the symbolic transition model is learned by inductive logic programming (ILP) to capture logic rules of state transitions. By planning over the product of the symbolic transition model and the automaton derived from the LTL formula, the agent can resolve causal dependencies and break a causally complex problem down into a sequence of simpler low-level sub-tasks. We evaluate the proposed framework on three environments in both discrete and continuous domains, showing advantages over previous representative methods.