Introduction
The objective of this research is to introduce the first application of Belief Propagation (BP), an iterative probabilistic algorithm, to both reputation and recommender systems. The research departs from the traditional approaches to solve for reputation and recommender problems in one major aspect: it formulates both problems as the inference problem while maintaining the dependency of the statistical data. This problem, however, cannot be solved in a large-scale reputation (and recommender) systems, because the number of terms grow exponentially with the number of nodes (i.e., users/items in reputation and recommender systems). The key benefit of the BP algorithm is that it solves the problem with the complexity that grows only linearly with the number of nodes.
The research views both the reputation management and recommendation problems as the inference problem involving the computation of the marginal probability distribution functions (of the reputation values or ratings to be predicted) from complicated global functions of many variables. This view maintains the statistical dependency of the data, and hence, results in robust and accurate systems. To compute these marginal distributions, the research then employs BP whose computational efficiency is derived by exploring the way in which the statistical data encoded on some forms of large graphical models, e.g., factor graphs. In particular, the project includes research to:
- Study the general theories of BP-based reputation management and recommender systems on various graphical models and develop novel algorithms
- Study the convergence, scalability, and robustness of the developed algorithms via the mathematical analysis and intensive simulations
- Evaluate the developed algorithms and compare them with the current state of art using real-life datasets and conducting user studies
- Adaptively learn various attack strategies against the reputation and recommender systems, determine the impacts of such attacks, and decrease their impact
This research is supported by the National Science Foundation under Grant No. IIS-1115199 and partially by a gift from the Cisco University Research Program Fund.
Research
 Reputation Systems via Belief Propagation
Reputation Systems via Belief Propagation-
Trust and reputation mechanisms have various application areas from online services to mobile ad-hoc networks (MANETs). Most well-known commercial websites such as eBay, Amazon, Netflix and Google use some types of reputation mechanisms. Despite recent advances in reputation systems, there is yet a need to develop reliable, scalable and dependable schemes that would also be resilient to various ways a reputation system can be attacked. We approach the reputation management problem as an inference problem and describe it as computing marginal likelihood distributions from complicated global functions of many variables. However, we observe that computing the marginal probability functions is computationally prohibitive for large scale reputation systems. Therefore, we propose to utilize the belief propagation algorithm to efficiently compute these marginal probability distributions, resulting in a belief propagation-based iterative trust and reputation management approach (BP-ITRM). Compared with some well-known reputation management techniques, e.g., Averaging Scheme, Bayesian Approach, and Cluster Filtering, BP-ITRM is superior in terms of robustness against common attacks such as ballot-stuffing and bad-mouthing. Finally, BP-ITRM introduces only a linear complexity in the number of service providers and consumers, and thus is suitable for deployment in large-scale systems.
- Recommender Systems on Factor Graphs
-
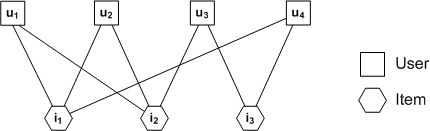
Recommender systems suggest to consumers items that meet their interests and preferences, which frees users from the overwhelming amount of available information. However, there are certain challenges to design scalable, accurate and dependable recommender systems, as the available data for the recommender systems is incomplete, uncertain, inconsistent and/or intentionally contaminated. Most existing popular Matrix Factorization recommender algorithms are shown to be prone to malicious behaviors and they have scalability issues. We formulate the recommendation problem as an inference problem and aim to compute the marginal probability distributions of the variables which represent the ratings of items to be predicted. By modeling the recommender system on a factor graph, we then utilize the Belief Propagation algorithm to efficiently calculate the marginal probability distributions through message-passing on the factor graph. The BP-based recommender system (BPRS) is comparable to the state of art methods such as Correlation-based neighborhood model (CorNgbr) and Singular Value Decomposition (SVD) in terms of rating and precision accuracy. Moreover, as opposed to the previous recommender algorithms, BPRS does not require solving the recommendation problem for all the users if it wishes to update the recommendations for only a single active user. Therefore, BP-based recommendation algorithm is a new promising approach which offers a significant advantage on scalability while providing competitive accuracy for the recommender systems.
- Recommender Systems on Pairwise Markov Random Fields
-
We formulate the recommendation problem as an inference problem on a Pairwise Markov Random Field (PMRF) to exploit both item similarity and user similarity. Given an active user, we model the unknown ratings on items as variable nodes in a PMRF. We further connect items using edges based on similarity relationships and construct local evidence nodes based on other similar users' ratings. However, direct prediction of ratings has exponential time complexity, as it requires to compute marginal probabilities. Thus, we utilize the Belief Propagation (BP) algorithm to solve the problem with a complexity that grows linearly with the number of items in the system. The BP algorithm computes marginal probabilities by performing iterative probabilistic message-passing between item nodes on the PMRF. Moreover, its complexity remains linear per active user. Via computer simulations using 100K MovieLens dataset, we verify that the proposed algorithm outperforms algorithms based only on user similarity in terms of both Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE).
- User Study via InfoXchange@GaTech
-
In this project, we develop a Georgia Tech Information-Exchange Platform for Education (InfoXchange@GaTech). This platform will serve two purposes:
- User study for our evaluation of the proposed schemes in reputation and recommender systems.
- A social network platform that would enhance and foster learning and education.
Currently, we are developing a web interface platform that we can perform a user study. The user study will play a crucial role in the evaluation of our reputation and recommender algorithms. This will help in validation and improvement of our method based on the user experiences of the prototype system.
Our ultimate intention is to lay out the foundation of a social network for education for information exchange services. The platform will enable students to discuss subjects among themselves and ask questions from each others. Our goal is to develop and test a pilot project at the Georgia Tech campus as a cyber-enabled virtual education community.
- Belief Propagation for Detecting Shilling Attacks
-
Recommender systems are increasingly employed by e-commerce websites, e.g., Amazon.com and Netflix.com, to provide personalized recommendations to users. They are efficient in retrieving information that meets user interests from a large volume of data, which is critical in today's online activities as a human being simply cannot handle the explosive amount of information on the Internet. Collaborative Filtering (CF) is so far the most popular recommendation algorithm, which relies on historic ratings given by users on items to make recommendations. Unfortunately, it is vulnerable to the so called ``shilling'' attacks, in which a group of spam users collaborate to influence the recommendations for their benefits, e.g., to recommend their products more often. In an attacked recommender system, users are recommended with flawed low quality products or products they do not like, which in turn decreases user satisfaction. Therefore, it is of practical interest and importance to protect the recommender systems against those shilling attacks.
To protect the recommender systems against such attacks, one of the major approaches is to detect the spam users and remove them from the system. The existing works introduced several metrics for detecting the rating patterns of spam users. However, those feature-based algorithms suffer from low accuracy, as they only look at individual user rating patterns. Another work exploited the statistical properties of spam users, e.g., covariance, to perform detection via variable selection using Principle Component Analysis (PCA-VarSel). PCA-VarSel is very effective when spam users have low covariance, e.g., when they rate items randomly selected from all items, because genuine users have high covariance since they mostly rate only the popular items. However, that PCA-VarSel easily fails if spam users also selectively rate only those popular items.
The existing detection algorithms in the literature focused extensively on rating patterns of individual spam users, such as those feature-based algorithms, but they do not take into account the relationships of users, and suffer from low accuracy. In our work, we develop a probabilistic inference framework that further exploits the user relationships for attack detection. In particular, we propose a factorized probabilistic model, and apply the efficient Belief Propagation (BP) algorithm for inference
- Top-N Recommendation in Social Networks
-
To counter the information overloading problem on the Internet, recommender systems have been widely employed by online service websites to suggest items, e.g., movies and books, to users who might like them. In typical practical implementations, a list of N items are rendered to an active user which he may find the most interesting. This is known as the top-N recommendation task. There are a variety of recommendation algorithms including content-based recommendations and collaborative recommendations. In content-based recommendations, each item is characterized by a set of attributes, based on which item similarity is estimated, and the active user will be recommended items similar to the ones he liked in the past. However, the content-based recommendation system suffers from limited content-analysis, e.g., it is difficult to explicitly describe multimedia data using features. Instead, in collaborative recommendations, also known as collaborative filtering, the active user will be recommended items favorably rated by other users with similar tastes to the active user. The user similarity can be estimated based on user profiles including detailed personal information, but due to privacy concerns they are very difficult to obtain. Hence, the collaborative recommender systems evaluate user similarity based on users' historic rating data. This causes the cold-start problem for new users or users who do not provide enough ratings, i.e., the recommender systems cannot find similar users for them.
Recently, with the thriving of online social networks (OSN), the social collaborative recommendation has attracted significant attention. In social networks, people are more likely to connect to other people sharing similar interests, and they are influenced more by people they connect to, further fostering similarity to each other. Hence, by exploiting the social structure of social networks, social recommender systems can make satisfactory recommendations even for cold-start users when provided with their social connections. Moreover, social recommendation can also be conveniently incorporated with traditional collaborative filtering algorithms, e.g., matrix factorization and neighborhood methods, improving their recommendation performance, especially for cold-start users.
Meanwhile, people are increasingly concerned with their online privacy, adding new challenges to the recommendation problem. Although rating data do not directly tell personal details, it is still possible to infer user demographics, such as age and gender, from their ratings, and even uncover user identities and reveal sensitive personal information with access to other databases. Therefore, users are not willing to make their personal data accessible to the general public. Hence, when designing collaborative recommendation systems, we need to take into account user privacy.
We propose a social recommendation algorithm that exploits the social network to generate recommendations using only the implicit user data, e.g., whether a user has consumed an item or not, avoiding exposing explicit user rating data.
- Trust Inference for Social Networks
-
The online social networks such as Facebook and Twitter are becoming important platforms for making social connections and sharing information. Meanwhile, the powerful personal mobile computing devices, e.g., smart phones and tablets, and the ubiquitous wireless communications enable users to participate in on-line social activities and process complicated social media data including texts, videos, images, and voices anywhere any time. Hence, social computing applications have attracted significant interest from both industry and government. However, due to the open nature of such social networking platforms, they are inherently vulnerable to malicious spam users who misuse social networks to perform spamming, phishing, and spreading false information. Such misbehaviors can greatly compromise the utility and functionality of social networks. Therefore, there is an urgent need to develop effective measures to evaluate the trust of users in social computing networks.
Most existing approaches focus on discovering patterns and features of users, and use them as input to classification machine learning tools, e.g., support vector machines, for automatic trust analysis. But such classification approaches determine the trust of each user separately from other users. However, users in social networks are naturally related to each other through social connections and interactions, and users share common ground usually exhibit close relationships. For example, recently the case study result on the Twitter social network has revealed that criminal user accounts tend to be socially connected to form a small-world network.
We develop an effective and efficient probabilistic inference framework for solving the trust inference problem in social computing networks. In particular, we formulate the problem in a Pairwise Markov Random Field (PMRF) that takes into count both user features and user relationships. PMRF is a probabilistic graphical model that expresses the factorization of a global function, and hence we can apply the Belief Propagation (BP) algorithm to perform inference efficiently. BP exploits the graph structure for computing marginal functions from global functions of many variables.
- Link Recommendation in Twitter Networks
-
Twitter is a popular on-line platform for social networking and information sharing. Twitter users can follow other users to receive messages, or tweets, from them. However, given the limited attention and time, most users would like to follow only the most relevant users. Due to the huge number of users in Twitter, recommendation algorithms are needed to help users automatically discover new interesting users to follow.
Many existing link recommendation algorithms for social networks are developed with focus on the link structure. The simplest example is to recommend the most popular users with the largest number of connections. Other common algorithms first weigh each link by some importance score, and rank the nodes according to the sum of importance scores of their links, e.g., the PageRank algorithm. We generally refer to those algorithms as "popularity" or "weighted popularity" based algorithms.
Yet, unlike other social networks such as Facebook, besides to establish social connections, many Twitter users follow other users to receive information interesting to them. Hence, it seems attractive to exploit the similarity between Twitter users for recommendation, i.e., to recommend other users similar to the followees already followed by the follower, or to recommend other users who are similar to the follower. There are two general classes of algorithms for this purpose: the content-based algorithm and the collaborative filtering algorithm. The content-based algorithms match user interests by directly analyzing the texts of tweets, whereas the collaborative filtering algorithms such as matrix factorization technique learn latent user interests from the user feedbacks, e.g., to follow a user or not.
We compare various popularity-based algorithms and similarity-based algorithms for Twitter user recommendation, and propose hybrid recommendation algorithms to exploit both popularity and similarity. Indeed, a recent study has shown that popularity and similarity are the two important factors that drive the growth of a variety of networks including the Internet and social networks
- Event Credibility Prediction in Twitter
-
Online social media services like Twitter are widely adopted by people to self-report activities and stories happening around them. Monitoring social media streams, e.g., tweets in Twitter, becomes an effective way to detect real-time events and monitor emergent situations. However, social media is also increasingly exploited to spread rumors and false information, e.g., fake images during Hurricane Sandy. False rumors in social media can potentially reach millions of people in short amount of time. Counter measures are thus needed to curb false information from undermining the integrity and utility of social media.
The existing works relied on offline aggregation analysis, where a complete set of tweets related to social events are required to extract aggregation features such as the depth of the propagation tree based on the retweets. However, because collecting a complete set of tweets often causes significant delay, this approach is not suitable when we need to detect false events as early as possible.
In this project, we develop a probabilistic generative model for real-time event credibility prediction with streaming tweets. We propose an online streaming prediction algorithm. In contrast to offline aggregation analysis that requires a complete set of tweets related to an event, the proposed algorithm only uses the currently observed streaming tweets. The algorithm updates prediction without the need to store or reprocess the past tweets. We conduct experiments on the dataset of tweets collected from Twitter.
- Distributed Collaborative Filtering with Cascaded Belief Propagation
-
Collaborative Filtering (CF) is the most popular recommendation algorithm, which exploits the collected historic user ratings to predict unknown ratings. However, traditional recommender systems run at the central servers, and thus users have to disclose their personal rating data to other parties. Previously, we proposed a semi-distributed Belief Propagation (BP) approach to privacy-preserving item-based CF recommender systems. We formulate the item similarity computation as a probabilistic inference problem on the factor graph, which can be efficiently solved by applying the BP algorithm. To avoid disclosing user ratings to the server or other user peers, we then introduce a semi-distributed architecture for the BP algorithm.
However, the semi-distributed BP architecture requires that all users be active and participate in BP message propagation at the same time. Yet, in practical scenarios, it is difficult to meet this stringent requirement due to various reasons, e.g., some users may not be active temporally. In this project, we further propose a cascaded BP scheme to address the practical issue that only a subset of users participate in BP during one time slot. Moreover, we analyze the privacy of the semi-distributed BP from a information-theoretic perspective.
Publications
- J. Zou and F. Fekri, "A Belief Propagation Approach to Privacy-Preserving Item-Based Collaborative Filtering," IEEE Journal of Selected Topics in Signal Processing, Special Issue on Signal and Information Processing for Privacy, vol. 9, No. 7, pp. 1306-1318, Oct. 2015. [PDF]
- J. Zou, F. Fekri, and S. W. McLaughlin, "Mining Streaming Tweets for Real-Time Event Credibility Prediction in Twitter," in Proceedings of IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM'15), Paris, France, Aug. 2015. [PDF]
- J. Zou and F. Fekri, "Leveraging Online Social Relationships for Predicting User Trustworthiness," in Proceedings of IEEE Global Communications Conference (GLOBECOM'15) - Social Networks Track, San Diego, CA, USA, Dec. 2015. [PDF]
- J. Zou and F. Fekri, "Exploiting Popularity and Similarity for Link Recommendation in Twitter Networks," in Proceedings of the 6th ACM RecSys Workshop on Recommender Systems and the Social Web (RSWeb'14), Foster City, CA, USA, Oct. 2014. [PDF]
- J. Zou and F. Fekri, "On Top-N Recommendation Using Implicit User Preference Propagation over Social Networks," in Proceedings of IEEE International Conference on Communications (ICC'14), Sydney, Australia, Jun. 2014. [pdf]
- J. Zou and F. Fekri, "A Belief Propagation Approach for Detecting Shilling Attacks in Collaborative Filtering," in Proceedings of the 22nd ACM International Conference on Information and Knowledge Management (CIKM'13), San Francisco, CA, USA, Oct. 2013. [pdf]
- J. Zou, A. Einolghozati, and F. Fekri, "Privacy-Preserving Item-Based Collaborative Filtering Using Semi-Distributed Belief Propagation," in Proceedings of the First IEEE Conference on Communications and Network Security (CNS'13), Washington, D.C., USA, Oct. 2013. [pdf]
- J. Zou, A. Einolghozati, E. Ayday, and F. Fekri, "Iterative Similarity Inference via Message Passing in Factor Graphs for Collaborative Filtering," in Proceedings of IEEE Information Theory Workshop (ITW'13), Seville, Spain, Sept. 2013. [pdf]
- E. Ayday, J. Zou, A. Einolghozati, and F. Fekri, "A Recommender System Based on Belief Propagation over Pairwise Markov Random Fields," in Proceedings of the 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton'12), Monticello, IL, USA, Oct. 2012. [pdf]
- E. Ayday, A. Einolghozati, and F. Fekri, "BPRS: belief propagation based iterative recommender system," in Proceedings of IEEE International Symposium on Information Theory (ISIT'12), Cambridge, MA, USA, July 2012. [pdf]
- E. Ayday and F. Fekri, "An iterative algorithm for trust management and adversary detection for delay tolerant networks," IEEE Transactions on Mobile Computing, vol. 11, no. 9, pp. 1514-1531, Sept. 2012. [pdf]
- E. Ayday and F. Fekri, "Iterative trust and reputation management using belief propagation," IEEE Transactions on Dependable and Secure Computing, vol. 9, no. 3, pp. 375-386, Mar. 2012. [pdf]
- E. Ayday and F. Fekri, "BP-P2P: belief propagation-based trust and reputation management for p2p networks," in Proceedings of IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON'12), Seoul, Korea, Jun. 2012. [pdf]
- E. Ayday and F. Fekri, "Robust reputation management using probabilistic message passing," in Proceedings of IEEE Global Communications Conference (GLOBECOM'11), Houston, TX, USA, Dec. 2011 [pdf]
- E. Ayday and F. Fekri, "Application of belief propagation to trust and reputation management," in Proceedings of IEEE International Symposium on Information Theory (ISIT'11), Saint-Petersburg, Russia, July 2011. [pdf]
Data Sets
User modeling for evaluation of reputation systems
To evaluate the proposed belief propagation based iterative trust and repuation management (BP-ITRM) algorithm, we generate ratings for service providers in the reputation systems through user modeling method to mimic the behavior of both non-malicious and malicious users. The detailed user model description is provided in our recent publication on reputation systems [1]. Our next step is to further evaluate BP-ITRM using real-life datasets such as those collected from eBay, Advogato, and Epinions.
- E. Ayday and F. Fekri, "Iterative trust and reputation management using belief propagation," IEEE Transactions on Dependable and Secure Computing, vol. 9, no. 3, pp. 375-386, 2012. [pdf]
Real-life data sets for evaluation of recommender systems
There are a couple of popular real-life rating data sets such as Netflix and MovieLens that are publicly available for evaluation of recommedation algorithms. We used the MovieLens data, collected from the MovieLens web site by GroupLens research lab at the University of Minnesota.
Evaluation by user study
We will set up a user study for evaluation and implementation of reputation and recommender systems since validation and improvement of our methods is mainly based on the user experiences of the prototype system. To achieve this goal, we are planning to develop a web-based virtual education portal InfoXchange@Gatech at the Georgia Tech campus, which will be an online information exchange platform.
Shilling attack dataset
We evaluate the performance of the proposed BP-based attack detection algorithm using the 100K MovieLens dataset. The dataset contains 100,000 ratings, all integers from 1 to 5, on 1682 items (movies) by 943 users. We treat the original users in the dataset as genuine users. To launch shilling attacks, a number of spam users are injected into the system. In particular, the Average attack model is adopted, where the rating on each filler item follows a normal distribution with its mean set as the average rating received by the filler item. Finally, a set of items are selected as targets in the attack.
Top-N recommendation in social networks
We evaluate the top-N recommendation performance of the proposed EP algorithm using the Epinions dataset. The dataset consists of 49,290 users and 139,738 items. A total of 664,824 ratings are given by users on items, and each rating is an integer between 1 and 5. The dataset also includes 487,181 directed trust statements with trust value one.
Trust inference in social networks
We use the Twitter dataset consisting of the real Twitter user profiles. The spam users are identified as those post URL links of malicious websites, e.g., phishing websites, by the SUCCESS research lab at the Texas A&M University. The crawled data for each user include the basic user profile information, e.g., account creation time, the list of followers and followings, and the most recent Tweets.
Link recommendation in Twitter networks
We evaluate the empirical performance on the Twitter dataset and the Tencent Weibo dataset. Tencent Weibo is a Twitter-like online microblogging service widely used in China. The Twitter dataset is downloaded from Twitter.com using Twitter API. The Tencent Weibo dataset is a subset of the dataset provided by KDD Cup 2012 Track 1.
Personnel
Faculty
Prof. Faramarz Fekri
School of Electrical and Computer Engineering
Georgia Institute of Technology
Students
Yashas Malur Saidutta
Ph.D. Student, ECE, Georgia Tech
Jun Zou
Ph.D. Student, ECE, Georgia Tech
Erman Ayday
Ph.D. Student, ECE, Georgia Tech
Arash Einolghozati
Ph.D. Student, ECE, Georgia Tech
Prachi K Shelgikar
Master Student, ECE, Georgia Tech
Jin Xu
Undergraduate Student, ECE, Georgia Tech
Collaborators
Erman Ayday
Post-Doctoral Researcher
Ecole Polytechnique Fédérale de Lausanne (EPFL), Switzerland
Sponsors
This research is supported by the National Science Foundation under Grant No. IIS-1115199, and a gift from the Cisco University Research Program Fund.


Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
Contact Us
Prof. Faramarz Fekri
Room 5238
Centergy One
75, 5th Street NW
Atlanta, GA - 30308
Phone (404) 894-3335
Email: fekri AT ece DOT gatech DOT edu